Актуальность. Современный этап развития цивилизации характеризуется переходом наиболее развитой части человечества от индустриального общества к информационному. Одним из наиболее ярких явлений этого процесса является возникновение и развития глобальной информационной компьютерной сети.
Проблема поиска и сбора информации — одна из важнейших проблем информационно поисковых систем. Конечно, нельзя сравнивать в этом отношении, скажем, средние века, когда поиск информации был проблемой потому, что этой информации было мало, и требовались усилия только для того, чтобы найти хоть что-то по более или менее значительному интересующему вопросу. Так, сначала появилась возможность пойти в библиотеку и, потратив там время на выбор нужной книги по каталогу, найти необходимую информацию. Но каталоги не решают полностью проблем поиска информации даже в рамках одной библиотеки, так как в каталожную запись входит относительно мало информации: заголовок, автор, место издания. Проблема поиска информации приобрела новый характер в 20-м столетии, с началом развития века информационных технологий. Теперь она заключается не в том, что информации мало и поэтому ее трудно найти, а в том, что ее теперь наоборот становится все больше и больше, и от этого найти ответ на интересующий вопрос может оказаться тоже довольно сложной задачей. Проблема поиска информации значительно усложняется при использовании виртуальных источников. Здесь используется технология онлайновых каталогов, в результате применения которой пользователь имеет возможность выполнять поиск в каталогах сразу нескольких библиотек, чем, на самом деле, еще больше усложняет себе задачу, но, с другой стороны, увеличивает шансы решить ее.
На современном этапе все информационное пространство, в котором мы живем, все больше погружается в Internet. Internet становится основной формой существования информации, не отменив традиционных, такие как журналы, радио, телевидение, телефон, всевозможные справочные службы.
Целью исследования является изучение автоматизированных информационно — поисковых систем.
Задачей в данной курсовой работе рассматриваются теоретические основы автоматизированного информационного поиска, классификация и разновидности информационно поисковых систем. Также анализируется материал по применяемым в настоящее время информационно — поисковым каталогам полнотекстовых и гипертекстовых поисковых систем.
Справочные правовые системы
... 12 лет работающая на российском рынке информационно-правовых услуг. Основной деятельностью Сети является распространение правовой информации. Справочно-правовая система «Консультант Плюс» открывает доступ к самым ... документов, поиск по ключевым словам, установление и отражение всех взаимосвязей документов). Большинство СПС позволяют не только быстро найти необходимую правовую информацию, но и ...
При появлении сети internet проблема поиска становилась более актуальной. Internet — всемирная компьютерная сеть, представляющая собой единую информационную среду и позволяющая получить информацию в любое время. Но с другой стороны в Интернете хранится очень много полезной информации, но для поиска её требуется затрачивать много времени. Эта проблема послужила поводом к появлению поисковых систем. В данной курсовой работе будут рассмотрены поисковые системы в сети Internet.
Информационно-поисковая система
Информационно-поисковая система (ИПС)
Каждая ИПС предназначена для решения определенного класса задач, для которых характерен свой набор объектов и их признаков. ИПС бывают двух типов : 1. Документографические . В документографических ИПС все хранимые документы индексируются специальным образом, т. е. каждому документу присваивается индивидуальный код, составляющий поисковый образ. Поиск идет не по самим документам, а по их поисковым образам. Именно так ищут книги в больших библиотеках. Сначала отыскивают карточку в каталоге, а затем по номеру, указанному на ней, отыскивается и сама книга.
2. Фактографические
Система управления базами данных
На настоящий момент существует множество различных СУБД. Наиболее широкую известность получили такие как Dbase , Clipper , FoxPro , Paradox , Microsoft Access .
Источники информации
[Электронный ресурс]//URL: https://pravsob.ru/referat/informatsionno-poiskovyie-pravovyie-sistemyi-obschaya-harakteristika/
Это такие популярные ресурсы Интернет, как WWW, группы новостей, списки рассылки и FTP-серверы. Безусловно, можно искать нужные источники информации вручную, узнавать адреса из специализированных журналов по информатике и Интернету, использовать специальные бумажные справочники с классифицированными по категориям адресами. Однако для такого изменчивого пространства как Интернет необходимо научиться пользоваться специальными инструментами, цель которых — собирать данные об информационных ресурсах и предоставлять пользователям услугу быстрого поиска.
ИПС (информационно-поисковая система)
ИПС (информационно-поисковая система)
Справочно-информационные правовые системы
... поставку СПС, сервисное обслуживание и передачу информации пользователям. Справочно-правовая система «Консультант Плюс» содержит самые разные типы правовой информации: от нормативных актов, материалов судебной ... из них — карточка поиска. Карточка поискапредставляет собой таблицу с некоторым количеством поисковых полей. Для каждого поискового поля в системе предусмотрен словарь, автоматически ...
Главной задачей любой ИПС является поиск информации релевантной информационным потребностям пользователя. Очень важно в результате проведенного поиска ничего не потерять, то есть найти все документы, относящиеся к запросу, и не найти ничего лишнего. Поэтому вводится качественная характеристика процедуры поиска — релевантность.
Релевантность
В общем случае, можно выделить следующие поисковые инструменты для WWW: каталоги, поисковые системы, метапоисковые системы.
Каталог
Поисковая машина
Адреса популярных поисковых машин за рубежом и в России.
Зарубежные
www.google
Российские поисковые системы:
www . yandex (или www . ya ) Рэмблер — www . rambler Апорт — www . aport
Метапоисковая машина
Обратите внимание на то, что различные поисковые системы описывают разное количество источников информации в Интернет. Поэтому нельзя ограничиваться поиском только в одной из указанных поисковых системах. Теперь познакомимся с инструментами поиска, которые не формируют собственный индекс, но умеют использовать возможности других поисковых систем. Это метапоисковые системы (поисковые службы) — системы, способные послать запросы пользователя одновременно нескольким поисковым серверам, затем объединить полученные результаты и представить их пользователю в виде документа со ссылками.
Адреса известных метапоисковых систем:
www.metacrawler
Поиск источников информации
[Электронный ресурс]//URL: https://pravsob.ru/referat/informatsionno-poiskovyie-pravovyie-sistemyi-obschaya-harakteristika/
Обсудим проблему поиска такого источника информации, как статьи в группах новостей. Инструментами поиска в данном случае могут являться рассмотренные поисковые машины WWW, которые индексируют не только пространство WWW, но и статьи в телеконференциях и имеют специальный режим поиска именно в этом ресурсе. Поиск в группах новостей поддерживает, например, поисковый сервер Altavistа. Следует отметить, что поисковые системы WWW весьма оперативно индексируют группы новостей и содержат информацию о статьях, реально существующих в сети. Для поиска в архивах новостей существую специализированные системы, самой известной из которых является система Deja ( www.deja ).
Классификация информационных систем в юридической деятельности
... — нет. ^ 2.1. Классификация информационных систем по степени автоматизации 1. Ручные информационные системы характеризуются отсутствием современных технических средств переработки информации и выполнением всех операций человеком. Например, о деятельности менеджера в фирме, где ...
Эта система позволяет проводить как поиск отдельных статей, содержащих введенный термин, так и поиск определенных групп новостей, посвященных обсуждению заданной темы. Можно зарегистрироваться в Deja и подписаться на определенные группы новостей.
Теперь рассмотрим инструменты, позволяющие проводить поиск файлов. Многие поисковые системы WWW стали оказывать услугу поиска мультимедийных файлов (Altavista, Aport).
Для этого вовсе нет необходимости знать специальные операторы, а достаточно перейти с домашней страницы по ссылкам Картинки (Images), MP3/Audio или Video к специальному режиму поиска. Поиск проводится по возможному имени файла или по тексту в комментарии к ссылке на мультимедийный файл.
Что касается поиска программного обеспечения, во всемирной паутине существуют поисковые Web-серверы с коллекциями условно-бесплатного ПО, некоторые из них специализируются на поиск программного обеспечения для Интернета или для конкретной операционной системы. Эти системы в конечном итоге приведут вас к конкретному серверу, с которого и можно скачать искомый программный продукт. Следует упомянуть серверы Archie, также оказывающие услугу поиска файлов на FTP-серверах, однако пользоваться Web-серверами гораздо удобнее.
Рассмотрим поисковые инструменты для поиска адресной информации. Введем понятие Белого(White) и Желтого (Yellow) поиска.
White-поиск
Yellow-поиск
Обычно Yellow Pages системы фактически сразу включают в себя и White Pages — у найденного адресата сразу видны его телефон и почтовый адрес. Кроме того, некоторые Yellow Pages позволяют искать просто в алфавитном списке своих абонентов (white-поиск).
С другой стороны, White pages также содержат элементы yellow-поиска — кроме задания собственного имени они обычно позволяют указать название города, штата и другие, сужающие поиск, данные (что необходимо в случае многих однофамильцев).
Возможно, именно поэтому многие on-line телефонные справочники, выполняющие, фактически white-поиск, называют себя Yellow pages.
Архитектура современных ИПС для WWW
Прежде чем описать проблемы построения информационно-поисковых систем Web и пути их решения рассмотрим типовую схему такой системы. В различных публикациях, посвященных конкретным системам, например [5,6], приводятся схемы, которые отличаются друг от друга только способом применения конкретных программных решений, а не принципом организации различных компонентов системы. Поэтому рассмотрим эту схему на примере, взятом из работы.
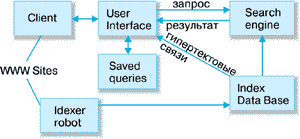
Рис 1. Типовая схема информационно-поисковой системы.
Client (клиент)
User interface (пользовательский интерфейс)
Search engine (поисковая машина)
Index database (индекс базы данных)
Queries (запросы пользователя)
Index robot (робот-индексировщик)
WWW sites
Рассмотрим теперь назначение по принципу построения каждого из этих компонентов, более подробно и определим, в чем отличие данной системы от традиционной ИПС локального типа.
Информационные ресурсы и их представление в ИПС
Как видно из рис. 1, документальным массивом ИПС Internet является все множество документов шести основных типов: WWW-страницы, Gopher-файлы, документы Wais, записи архивов FTP, новости Usenet и статьи почтовых списков рассылки. Все это довольно разнородная информация, которая представлена в виде различных, никак несогласованных друг с другом форматов данных: тексты, графическая и аудиоинформация и вообще все, что имеется в указанных хранилищах. Естественно возникает вопрос — как информационно-поисковая система должна со всем этим работать?
В традиционных системах используется понятие поискового образа документа — ПОД. Обычно, этим термином обозначают нечто, заменяющее собой документ и использующееся при поиске вместо реального документа. Поисковый образ является результатом применения некоторой модели информационного массива документов к реальному массиву. Наиболее популярной моделью является векторная модель, в которой каждому документу приписывается список терминов, наиболее адекватно отражающих его смысл. Если быть более точным, то документу приписывается вектор размерности, равный числу терминов, которыми можно воспользоваться при поиске. При булевой векторной модели элемент вектора равен 1 или 0, в зависимости от наличия или отсутствия термина в ПОД. В более сложных моделях термины взвешиваются — элемент вектора равен не 1 или 0, а некоторому числу (весу), отражающему соответствие данного термина документу. Именно последняя модель стала наиболее популярной в ИПС Internet.
Вообще говоря, существуют и другие модели описания документов: вероятностная модель информационных потоков и поиска и модель поиска в нечетких множествах. Не вдаваясь в подробности, имеет смысл обратить внимание на то, что пока только линейная модель применяется в системах Lycos, WebCrawler, AltaVista, OpenText и AliWeb. Однако ведутся исследования по применению и других моделей, результаты которых отражены в работах. Таким образом, первая задача, которую должна решить ИПС, — это приписывание списка ключевых слов документу или информационному ресурсу. Именно эта процедура и называется индексированием. Часто, однако, индексированием называют составление файла инвертированного списка, в котором каждому термину индексирования ставится в соответствие список документов в которых он встречается. Такая процедура является только частным случаем, а точнее, техническим аспектом создания поискового аппарата ИПС. Проблема, связанная с индексированием, заключается в том, что приписывание поискового образа документу или информационному ресурсу опирается на представление о словаре, из которого эти термины выбираются, как о фиксированной совокупности терминов. В традиционных системах существовало разбиение на системы с контролируемым словарем и системы со свободным словарем. Контролируемый словарь предполагал ведение некоторой лексической базы данных, добавление терминов в которую производилось администратором системы, и все новые документы могли быть заиндексированы только теми терминами, которые были в этой базе данных. Свободный словарь пополнялся автоматически по мере появления новых документов. Однако на момент актуализации словарь также фиксировался. Актуализация предполагала полную перезагрузку базы данных. В момент этого обновления перегружались сами документы, и обновлялся словарь, а после его обновления производилась переиндексация документов. Процедура актуализации занимала достаточно много времени и доступ к системе в момент ее актуализации закрывался.
Теперь представим себе возможность такой процедуры в анархичном Internet, где ресурсы появляются и исчезают ежедневно. При создании программы Veronica для GopherSpace предполагалось, что все серверы должны быть зарегистрированы, и таким образом велся учет наличия или отсутствия ресурса. Veronica раз в месяц проверяла наличие документов Gopher и обновляла свою базу данных ПОД для документов Gopher. В World Wide Web ничего подобного нет. Для решения этой задачи используются программы сканирования сети или роботы-индексировщики. Разработка роботов — это довольно нетривиальная задача; существует опасность зацикливания робота или его попадания на виртуальные страницы. Робот просматривает сеть, находит новые ресурсы, приписывает им термины и помещает в базу данных индекса. Главный вопрос заключается в том, что за термины приписывать документам, откуда их брать, ведь ряд ресурсов вообще не является текстом. Сегодня роботы обычно используют для индексирования следующие источники для пополнения своих виртуальных словарей: гипертекстовые ссылки, заголовки, аннотации, списки ключевых слов, полные тексты документов, а также сообщения администраторов о своих Web-страницах. Для индексирования telnet, gopher, ftp, нетекстовой информации используются главным образом URL, для новостей Usenet и почтовых списков поля Subject и Keywords. Наибольший простор для построения ПОД дают HTML документы. Однако не следует думать, что все термины из перечисленных элементов документов попадают в их поисковые образы. Очень активно применяются списки запрещенных слов (stop-words), которые не могут быть употреблены для индексирования, общих слов (предлоги, союзы и т.п.).
Таким образом даже то, что в OpenText, например, называется полнотекстовым индексированием реально является выбором слов из текста документа и сравнением с набором различных словарей, после которого термин попадает в ПОД, а потом и в индекс системы. Для того чтобы не раздувать словарей и индексов (индекс системы Lycos уже сегодня равен 4 Тбайт), применяется такое понятие, как вес термина. Документ обычно индексируется через 40 — 100 наиболее «тяжелых» терминов.
Индекс поиска
После того как ресурсы заиндексированы и система составила массив ПОД, начинается построение поискового аппарата. Совершенно очевидно, что лобовой просмотр файла или файлов ПОД займет много времени, что абсолютно не приемлемо для интерактивной системы WWW. Для ускорения поиска строится индекс, которым в большинстве систем является набор связанных между собой файлов, ориентированных на быстрый поиск данных по запросу. Структура и состав индексов различных систем могут отличаться друг от друга и зависят от многих факторов: размер массива поисковых образов, информационно-поисковый язык, размещения различных компонентов системы и т.п. Рассмотрим структуру индекса на примере системы, для которой можно реализовывать не только примитивный булевый, но и контекстный и взвешенный поиск, а также ряд других возможностей, отсутствующие во многих поисковых системах Internet, например Yahoo. Индекс рассматриваемой системы состоит из таблицы идентификаторов страниц (; line-height: 150%»>«секретом фирмы» и ее гордостью.
Информационно-поисковый язык системы
Индекс — это только часть поискового аппарата, скрытая от пользователя. Второй частью этого аппарата является информационно-поисковый язык (ИПЯ), позволяющий сформулировать запрос к системе в простой и наглядной форме. Уже давно осталась позади романтика создания ИПЯ, как естественного языка, — именно этот подход использовался в системе Wais на первых стадиях ее реализации. Если даже пользователю предлагается вводить запросы на естественном языке, то это еще не значит, что система будет осуществлять семантический разбор запроса пользователя. Проза жизни заключается в том, что обычно фраза разбивается на слова, из которых удаляются запрещенные и общие слова, иногда производится нормализация лексики, а затем все слова связываются либо логическим AND, либо OR. Таким образом , запрос типа :
>Software that is used on Unix Platform
>
что будет означать примерно следующее: «Найди все документы, в которых слова Unix, Platform и Software встречаются одновременно». Возможны и варианты. Так, в большинстве систем фраза «Unix Platform» будет опознана как ключевая фраза и не будет разделяться на отдельные слова. Другой подход заключается в вычислении степени близости между запросом и документом. Именно этот подход используется в Lycos. В этом случае в соответствии с векторной моделью представления документов и запросов вычисляется их мера близости. Сегодня известно около дюжины различных мер близости. Наиболее часто применяется косинус угла между поисковым образом документа и запросом пользователя. Обычно эти проценты соответствия документа запросу и выдаются в качестве справочной информации при списке найденных документов.
Наиболее развитым языком запросов из современных ИПС Internet обладает Alta Vista. Кроме обычного набора AND, OR, NOT эта система позволяет использовать еще и NEAR, позволяющий организовать контекстный поиск. Все документ в системе разбиты на поля, поэтому в запросе можно указать, в какой части документа пользователь надеется увидеть ключевое слово: ссылка, заглавие, аннотация и т.п. Можно также задавать поле ранжирования выдачи и критерий близости документов запросу.
информационным поиском
Массив элементов информации, в котором производится информационный поиск, называется поисковым массивом. Существующие виды информационного обслуживания представлены втаблице:
|
Признак классификации |
Вид обслуживания |
|
По источнику инициативы |
— по запросам потребителей |
|
По типам документов |
— обслуживание копиями неопубликованных документов (отчетов по НИР, диссертаций, переводов и т. п.) |
|
По направленности или адресности |
— избирательное распределение информации (один адрес) |
|
По периодичности или срочности |
— ретроспективный поиск |
|
По способу доведения документов до потребителя |
|
Заключение
Рассмотренные мною поисковые машины далеки от совершенства. Считается, что идеальная поисковая машина должна отвечать следующим требованиям:
-
. быстрый поиск в базе данных и быстрое реагирование.
-
. надёжность и точность результатов поиска.
-
. простота в использовании
-
. чётко организованный и обновляемый индекс.
Масштабы информационных ресурсов и их количество постоянно расширяется. Становится ясно, что база данных не является совершенной. Интеллектуальные агенты — новое направление лежащее в основе нового поколения поисковых машин, которые могут фильтровать информацию и получать более точный результат. Internet продолжает развиваться с неослабевающей интенсивностью, по сути дела стирая ограничение на распространение и получение информации в мире. Однако в этом информационном океане бывает не очень легко найти необходимый документ, следует также иметь в виду, что в сети наряду с давно действующими серверами возникают новые.
Список используемой литературы
[Электронный ресурс]//URL: https://pravsob.ru/referat/informatsionno-poiskovyie-pravovyie-sistemyi-obschaya-harakteristika/
1. Ашманов, И. С. Продвижение сайта в поисковых системах / И. С. Ашманов. — М. : «Вильямс», 2007. — 304 с.
2. Байков, В. Д. Интернет. Поиск информации. Продвижение сайтов / В. Д. Байков. — СПб.: БХВ- Петербург, 2000. — 288 с.
3. Ландэ, Д. В. Поиск знаний в Internet / Д. В. Ландэ. — М. : «Диалектика», 2005. — 272 с.
4. Чурсин, Н. А. Популярная информатика / Н. А. Чурсин.- М.: «Вильямс», 2007.- 300 с.
5. Схемы и рисунки ИПС [Электронный ресурс]. — Режим доступа : http://ssofta.narod.ru/bd/ets2.htm
6. Структура и классификация автоматизированных информационных систем Режим доступа:
7. Схемы и рисунки ИПС [Электронный ресурс]. — Режим доступа: http://ssofta.narod.ru/bd/ets2.htm